Hadoop Namenode HA 구성하기
Hadoop/설치기존에 설치했던 Hadoop은 멀티 노드 구성이지만 Namenode가 1개로 Namenode에 문제가 생길 경우 서비스를 계속할 수 없습니다. 따라서 Namenode를 2개로 구성하여 문제 발생 시에도 계속 서비스가 가능하도록 설정하도록 하겠습니다.
1. 서버 구성
서버는 Multi-Server 구성 그대로 4대를 이용하며, 2대는 Namenode 로 3대는 Datanode로 구성합니다. 물리 서버는 4대인데 역할은 5대가 되므로 hadoop02는 Namenode 와 Datanode 를 겸합니다.
1.1 core-site.xml
core-site.xml 파일을 아래와 같이 변경해 줍니다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-cluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
fs.defaultFS 부분에 나오는 hadoop-cluster 가 namenode 클러스터명이 됩니다. 이 값은 임의로 원하는 값으로 바꾸면 됩니다.
ha.zookeeper.quorum 부분에 저널노드의 서버명:포트 순으로 넣어 줍니다. 저널노드는 3, 5, 7등 복수의 홀수개로 구성되어야 합니다. 여기서는 hadoop01~03을 이용합니다.
1.2 hdfs-site.xml
hdfs-site.xml을 아래와 같이 변경해 줍니다
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/hadoopdata/hdfs/journalnode</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>hadoop-cluster</value>
</property>
<property>
<name>dfs.ha.namenodes.hadoop-cluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop-cluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.hadoop-cluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/hadoop-cluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoop-cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<!-- Automatic failover configuration -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
dfs.nameservices에는 namenode 클러스터 명을 기입합니다.
이 후 나오는 dfs.ha.nameservices.<cluster-id> 와 dfs.namenode.xxx.<cluster-id> 부분에도 namenode 클러스터명을 기입합니다.
dfs.namenode.rpc-address 는 네임노드 서비스의 Host address 와 port 입니다. 네임노드는 2개 까지 가능하므로 nn1 과 nn2의 호스트가 되는 hadoop01 과 hadoop02 를 기입합니다.
dfs.namenode.http-address 는 웹 서비스 어드레스와 port입니다.
dfs.namenode.shared.edits.dir 에는 저널노드를 입력합니다. 여기서는 저널노드가 hadoop01~03이므로 위와 같이 입력합니다.
dfs.ha.fencing.methods 부분은 주키퍼가 담당하므로 shell(/bin/true)로 변경해 줍니다.
1.3 yarn-env.sh
yarn-env.sh파일은 아래와 같이 Heap 사이즈만 수정해 줍니다. 최대값을 1기가로 설정하겠다는 의미입니다.
JAVA_HEAP_MAX=Xmx1000m1.4 yarn-site.xml
yarn-site.xml파일을 아래와 같이 수정해 줍니다.
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/home/hadoop/hadoopdata/yarn/nm-local-dir</value>
</property>
<property>
<name>yarn.resourcemanager.fs.state-store.uri</name>
<value>/home/hadoop/hadoopdata/yarn/system/rmstore</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>0.0.0.0:8089</value>
</property>
</configuration>
1.5 설정파일 전송
모든 설정 파일을 다른 hadoop 서버로 전송해 줍니다. 아래 명령을 이용합니다.
scp $HADOOP_HOME/etc/hadoop/* hadoop02:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/* hadoop03:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/* hadoop04:$HADOOP_HOME/etc/hadoop/2. 하둡 실행
2.1 기존 데이터 제거
기존 구성의 데이터와 충돌이 발생할 수 있으므로 아래 명령으로 모든 데이터를 제거합니다.
이 작업은 4대의 서버 모두에서 각각 수행합니다.
cd ~
rm -rf hadoopdata/*/*2.2 주키퍼 포맷
하둡 실행 전에 먼저 주키퍼를 초기화 해 줍니다.
아래 명령으로 주키퍼를 포맷합니다. (이 작업은 hadoop01에서만 합니다).
$HADOOP_HOME/bin/hdfs zkfc -formatZK2.3 저널노드 시작
다음 명령으로 저널 노드 서비스를 시작합니다.
이 작업은 hadoop01 ~ 03 까지 저널노드 서버 모두에서 각각 수행합니다.
$HADOOP_HOME/bin/hdfs --daemon start journalnode2.4 Active 네임노드 실행
hadoop01 서버에서만 실행합니다.
먼저 다음 명령으로 hdfs를 포맷해 줍니다.
hdfs namenode -format이제 Active 네임노드를 실행합니다.
$HADOOP_HOME/bin/hdfs --daemon start namenode2.5 Standby 네임노드 실행
이제 대기중인 Standby 네임노드를 실행합니다. 이 작업은 hadoop02 서버에서 실행합니다.
먼저 아래 명령으로 Active 네임노드의 메타데이터를 복사해 옵니다.
hdfs namenode -bootstrapStandby이 명령이 성공하면 아래와 같이 나옵니다.
=====================================================
About to bootstrap Standby ID nn2 from:
Nameservice ID: hadoop-cluster
Other Namenode ID: nn1
Other NN's HTTP address: http://hadoop01:50070
Other NN's IPC address: hadoop01/192.168.35.122:8020
Namespace ID: 455152348
Block pool ID: BP-1247003603-192.168.35.122-1563595795113
Cluster ID: CID-143cb533-296b-4297-9b48-dd7749f351f1
Layout version: -63
isUpgradeFinalized: true
=====================================================메타데이터 복사가 완료되면 네임노드를 실행합니다.
$HADOOP_HOME/bin/hdfs --daemon start namenode2.6 ZooKeeper 장애 컨트롤러 (zkfc) 시작
이제 네임노드 2군데(hadoop01, hadoop02)에서 zkfc를 시작해 줍니다. 주키퍼가 장애여부를 판단하여 장애 발생 시 Standby 네임노드를 Active로 바꾸어 줍니다.
$HADOOP_HOME/bin/hdfs --daemon start zkfc2.7 데이터노드 시작
hadoop02 ~ 04 까지 데이터 서버에서 각각 아래 명령을수행합니다.
$HADOOP_HOME/bin/hdfs --daemon start datanode2.8 yarn 서비스 시작
다음 명령으로 yarn서비스를 시작합니다.
이 작업은 hadoop01서버에서 실행합니다.
start-yarn.sh2.9 히스토리 서버 시작
hadoop01,02 서버 에서 아래 명령으로 히스토리 서버를 시작합니다.
$HADOOP_HOME/bin/mapred --daemon start historyserver3. 서버 구동 확인
3.1 commnd-line 확인
jps 명령으로 서버들이 잘 구동중인지 확인합니다.
아래와 같이 나오면 정상입니다.
<hadoop01>
14960 Jps
13585 WebAppProxyServer
14401 NameNode
12803 JournalNode
13189 ResourceManager
13022 DFSZKFailoverController<hadoop02>
22949 DFSZKFailoverController
23061 NodeManager
18934 JobHistoryServer
22694 DataNode
22600 NameNode
22809 JournalNode
25305 Jps3.2 Web 확인
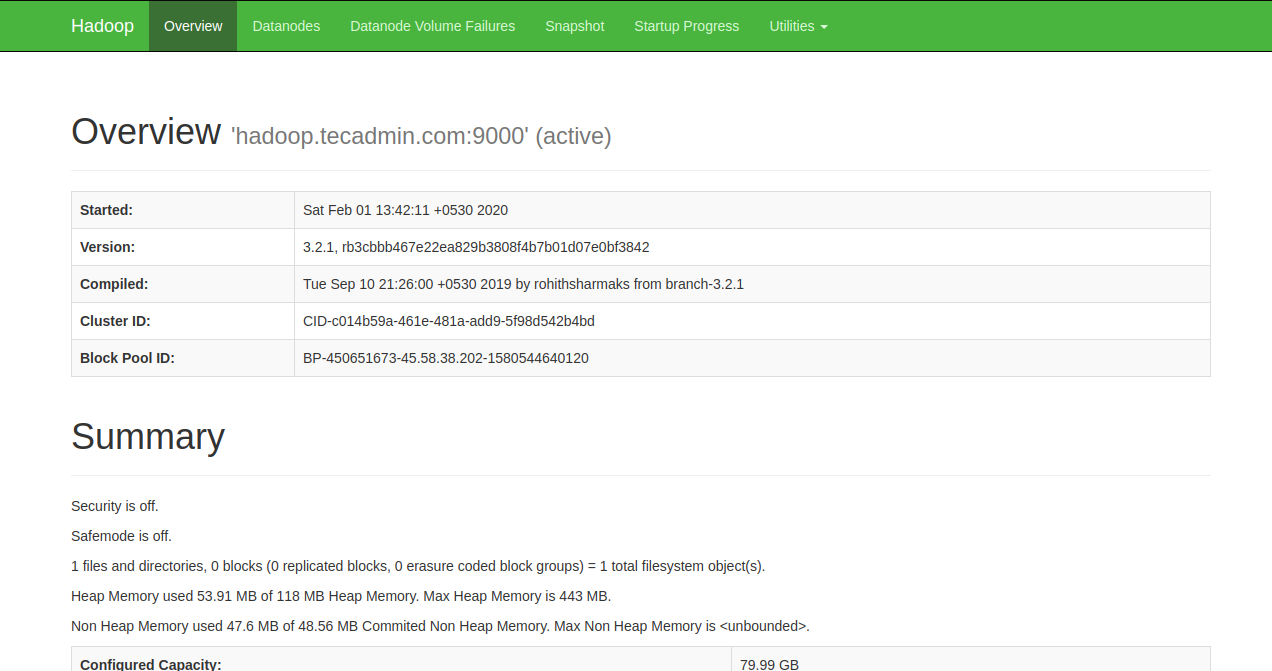
웹브라우저에서 http://hadoop01:50070 과 http://hadoop02:50070 으로 확인합니다.
Active 와 Standby 가 표시 되어야 정상입니다.