6) Side Bar 에서 Open Editors 항목 끄기 Settings - open editor - 숫자를 0으로 설정 사유: Ctl-P를 눌러서 Open Files 창에서 처리 가능함
7) 설정을 Json 형식 으로 바꾸기 Settings - settings json - UI -> Json 으로 변경
8) UI 형식 설정화면 바로가기 생성 커맨드창 - Preference : Open Keyboard Shortcut 선택 검색에서 Settings UI 넣고 키 바인딩에서 Ctl-Alt-, 로 설정 사유: 잘 모르는 항목 검색이 필요할 경우 설정에서 잘 모르면 검색 부분에 원하는 내용을 넣으면 인공지능을 이용해 찾아주므로 때때로 UI 형식 설정이 필요함.
유용한 Hot Key 정리
기본 Hot Key
커맨드 창 열기: Ctl-Shift - P 설정 Ctl - , Sidebar 보이기/숨기기 : Ctl - B 하단 패널(Output) 보이기/숨기기 : Ctl-J
Open 파일리스트 : Ctl-P 위 창에서 메쏘드 리스트 @ 위 창에서 문자열로 메쏘드 검색 #문자열 @: 분류별로 보여 줌 (CPP인 경우는 헤더에서)
Split Editor Ctl-\ : 현재 편집 중 화면을 우측으로 분리 Ctl-K Ctl-\ : 현재 편집 중 화면을 아래쪽으로 분리
Editing Hot Key
Alt - 화살표 : 라인 이동 Alt Shift - 화살표 : 라인 복사 Ctl Shift - K : 라인 삭제 브라켓(Bracket) 매칭: Ctl-Shift-\
Ctl Shift - L : 현재 커서와 일치하는 단어 모두 선택 Ctl - D: 현재 커서와 일치하는 단어 모두 선택 계속 누르면 다음으로 이동 Ctl - K: 위에서 해당 내용 건너 뜀
검색 시 regex 검색 가능 검색 후에 Alt-Enter 누르고 화살표 이동 후에 전체 변경 가능
찾기 Ctl-F
GIT
Ctl-Shift G : Open GIT Window Window 에서 Comment 넣고 Ctl-Enter 하면 Commit Push 하는 건 Windows ...메뉴에서 Push 하거나 우측 하단 Sync 아이콘 누름 (Sync 와 Push 의 차이는 Sync 는 Pull 을 먼저 하고 Push를 함)
Apache ZooKeeper는 탄력적이고 안정적인 분산 조정을 가능하게하는 오픈 소스 소프트웨어입니다. 일반적으로 분산 시스템에서 구성 정보, 이름 지정 서비스, 분산 동기화, 쿼럼 및 상태를 관리하는 데 사용됩니다. 또한 분산 시스템은 ZooKeeper를 사용하여 합의, 리더 선택 및 그룹 관리를 구현합니다.
RHEL/CentOS 8에Zookeeper를 설치하는 방법을 정리해 봅니다.
1. 서버 기본 설정
각 서버의 공통 설정은 Hadoop 설치를 참고합니다.
2. Zookeeper 설치
2.1 zookeeper 사용자 생성
보안을 생각해서 별도의 zk 사용자를 생성합니다.
아래 명령어로 새로운 사용자를 생성하고 암호를 설정해 줍니다:
useradd zk
passwd zk
이후에 아래와 같이 sshd_config를 수정해서 sshd를 통해 로그인이 불가능하도록 합니다.:
tickTime: tick 길이를 밀리 초 단위로 설정합니다.
tick은 ZooKeeper에서 하트 비트 사이의 길이를 측정하는 데 사용하는 시간 단위입니다.
최소 세션 시간 제한은 tickTime의 두 배입니다.
dataDir: 메모리 내 데이터베이스의 스냅샷 및 업데이트를위한 트랜잭션 로그를 저장하는 데 사용되는 디렉터리를 지정합니다.
트랜잭션 로그에 대해 별도의 디렉터리를 지정하도록 선택할 수 있습니다.
clientPort: 클라이언트 연결을 수신하는 데 사용되는 포트입니다.
maxClientCnxns: 최대 클라이언트 연결 수를 제한합니다.
3. Zookeeper 시작 및 테스트
3.1 zookeeper 서비스 시작
아래 명령어로 zk 사용자로 전환 후 zookeeper 디렉토리로 갑니다.
su -l zk
cd /opt/zookeeper
아래와 같이 zkServer.sh 명령을 실행합니다.
bin/zkServer.sh start
아래와 같은 실행결과가 화면에 표시되면 정상입니다.
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
3.2 zookeeper 테스트
아래 명령어로 로컬 ZooKeeper 서버에 접속합니다.
bin/zkCli.sh -server 127.0.0.1:2181
아래와 같이 CONNECTED 프롬프트가 나오면 정상입니다.
Connecting to 127.0.0.1:2181
...
...
[zk: 127.0.0.1:2181(CONNECTED) 0]
위 프롬프트에서 help 명령어를 입력하고 엔터를 칩니다. 그럼 아래와 같이 표시됩니다.
[zk: 127.0.0.1:2181(CONNECTED) 0] help
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
Hadoop은 머신 클러스터에서 대규모 데이터 세트를 저장하고 처리하는 데 사용되는 무료 오픈 소스 및 Java 기반 소프트웨어 프레임 워크입니다. HDFS를 사용하여 데이터를 저장하고 MapReduce를 사용하여 이러한 데이터를 처리합니다. 주로 데이터 마이닝 및 머신 러닝에 사용되는 빅 데이터 도구의 생태계입니다. Hadoop Common, HDFS, YARN 및 MapReduce와 같은 네 가지 주요 구성 요소가 있습니다.
RHEL/CentOS 8에 Apache Hadoop을 설치하는 방법을 정리해 봅니다.
1. 서버 기본 설정
각각의 서버에서 공통적으로 해야 하는 설치 및 설정입니다
1.1 고정IP 설정
각각의 서버에 고정IP를 설정해 줍니다. (고정IP는 각각의 서비스 상황에 맞게 IP를 설정합니다. 여기서는 81~84를 부여합니다)
고정IP 설정을 위해 아래 명령으로 파일을 수정합니다:
vi /etc/sysconfig/network-scripts
수정할 내용은 아래와 같습니다:
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none" <-- dhcp 를 none로 변경
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="enp1s0"
UUID="d5f41bf4-de0a-43b3-b633-7e2ec6212e58"
DEVICE="enp1s0"
ONBOOT="yes"
IPADDR=192.168.122.81 <-- 여기서 아래 부분 추가
PREFIX=24
GATEWAY=192.168.122.1
DNS1=192.168.122.1
DNS2=1.1.1.1
파일을 저장한 후 위의 DEVICE 부분의 인터페이스를 재시작 해서 IP를 변경내용을 적용합니다.
ifdown enp1s&& ifup enp1s0
바뀐 IP가 제대로 적용되었는 지 아래 명령으로 확인합니다.
ip addr | grep enp1s0
2.2 hostname 설정
서비스를 구성하는 각각의 서버의 서버명을 설정합니다. (여기서는 4대의 서버로 hadoop01 ~ hadoop04로 설정합니다)
아래 명령으로 각각의 서버명을 설정해 줍니다:
hostnamectl set-hostname hadoop01
hostname 설정이 되었다면 이제 각 서버마다 host명으로 접근이 가능하도록 /etc/hosts 파일에 추가해 줍니다.
Hadoop 은 Java로 작성되었고 최신 버전은 Java11도 지원하지만 아직은 Java 8에서 안정적입니다. 아래와 같이 DNF를 이용해서 OpenJDK 8을 설치합니다:
dnf install java-1.8.0-openjdk.x86_64 ant -y
설치 후 아래 명령으로 제대로 설치 되었는 지를 테스트 합니다:
java -version
다음 출력이 나오면 OK:
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)
1.4 Hadoop 사용자 생성
보안을 생각해서 별도의 Hadoop 사용자를 생성합니다.
아래 명령어로 새로운 사용자를 생성합니다:
useradd -m hadoop
다음으로 생성한 사용자의 암호를 설정해 줍니다:
passwd hadoop
아래와 같이 사용자에 대한 암호를 2번 입력합니다:
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
1.5 Configure SSH Key-based Authentication
패스워드 없이 접속이 가능하도록 ssh 키를 설정합니다.
다음 명령으로 hadoop 유저로 로그인 합니다.
su - hadoop
다음 명령으로 공개키와 개인키를 생성합니다.
ssh-keygen -t rsa
아래와 같이 물어 보게 되는 데 엔터만 치면 됩니다.
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:a/og+N3cNBssyE1ulKK95gys0POOC0dvj+Yh1dfZpf8 hadoop@centos8
The key's randomart image is:
+---[RSA 2048]----+
| |
| |
| . |
| . o o o |
| . . o S o o |
| o = + O o . |
|o * O = B = . |
| + O.O.O + + . |
| +=*oB.+ o E|
+----[SHA256]-----+
처음 1번은 아래와 같이 호스트를 등록할 거냐고 물어 본니다. yes를 하고 엔터를 누르면 정상적으로 접속됩니다.
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:0YR1kDGu44AKg43PHn2gEnUzSvRjBBPjAT3Bwrdr3mw.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Sat Feb 1 02:48:55 2020
[hadoop@centos8 ~]$
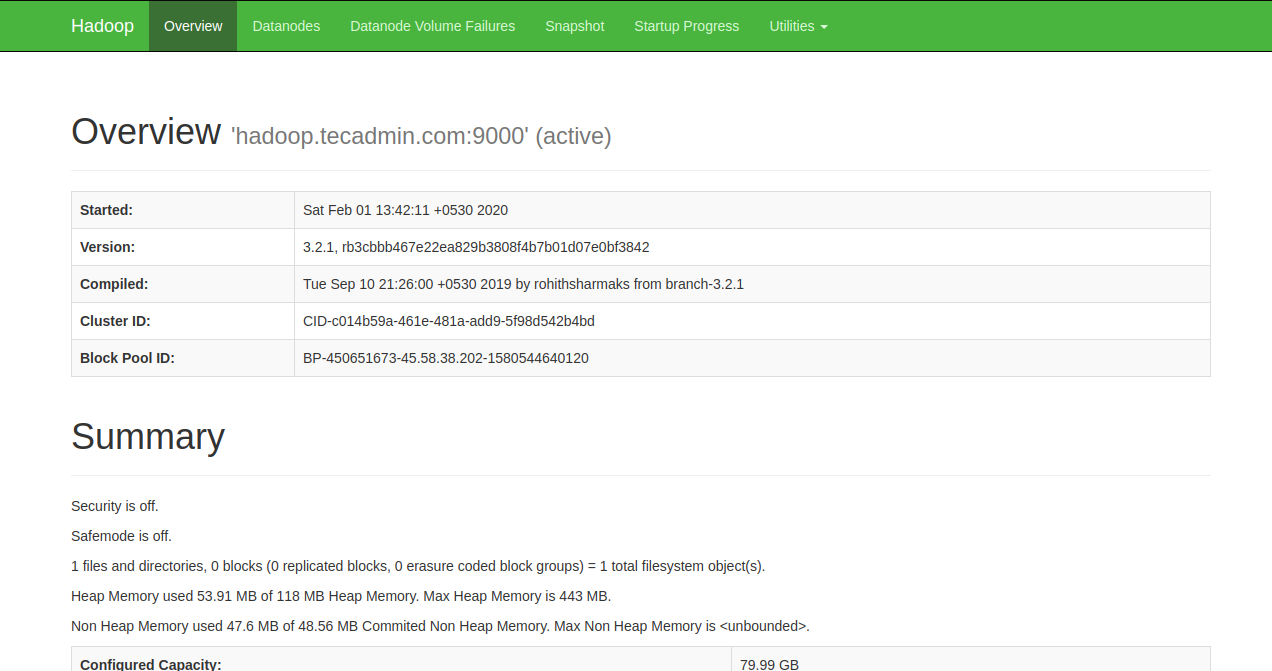
Hadoop 클러스터를 시작하기 전에 먼저 hadoop 사용자로 Namenode를 포맷해야 합니다.
Namenode를 포맷하기 위해 아래 명령어를 실행합니다:
hdfs namenode -format
아래 내용이 표시되면 성공입니다:
2020-02-05 03:10:40,380 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-02-05 03:10:40,389 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2020-02-05 03:10:40,389 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.com/45.58.38.202
************************************************************/
Namenode 포맷 후에, 아래 명령으로 hadoop 클러스트를 시작합니다:
start-dfs.sh
HDFS 성공적으로 시작되면, 아래와 같은 내용이 표시됩니다:
Starting namenodes on [hadoop.tecadmin.com]
hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [hadoop.tecadmin.com]
VPN 서비스는 외국에서 한국의 서비스를 이용하거나, mVOIP 사용량 제한을 우회하기 위해 많이 사용됩니다. 이번에 중국에 지인이 있어서 중국의 만리 방화벽을 뚫을 수 있는 VPN 서비스를 찾다 보니 일반 공유기가 지원하는 L2TP 또는 PPTP등의 VPN 서비스는 만리 방화벽에 막혀서 안된다고 합니다. 그래서 가능한 방법을 찾아보니 IKEv2 VPN은 가능하다고 하는데 놀고 있는 Orange Pi 에 올려서 서비스를 해 보고자 방법을 찾아 공유를 합니다. Orange Pi 여서 Armbian 기준이며, id/password 방식을 사용하려면 mschapv2 플러그인이 필요한데 armbian 기본 패키지에서는 제공이 안되서 소스 컴파일 하여 설치를 하였습니다. Raspbian 에서도 잘 될 것으로 보이며, Raspbian 에서는 apt 설치 패키지에 mschapv2 플러그인이 있다면 설치 패키지를 사용하는 편이 시간이 절약될 것으로 보입니다.
1. Letsencrypt 인증서 발급
Ikev2 서버를 사용자 id/password 를 이용하여 접속하기 위해서는 인증서가 필요합니다. 무료인증서인 Let's Encrypt 인증서를 발급 받습니다.
아래 명령으로 Strongswan Server를 소스에서 컴파일 하여 설치합니다.. 설치되는 위치는 /usr/local/strongswan 입니다.
# tar xvzf ../down/strongswan-5.8.0.tar.gz
# cd strongswan-5.8.0
# ./configure --prefix=/usr/local/strongswan --sysconfdir=/etc --enable-openssl --enable-eap-mschapv2 --enable-md4
# make
# make install
5. 인증서 파일 링크
아래의 명령과 같이 1에서 발급 받은 인증서를 해당위치로 링크해 줍니다. 3군데 위치로 심볼릭 링크(또는 복사)해 주어야 하며, 아래에서 your.domain.name 부분을 자신의 도메인으로 수정해야 합니다.
파일을 아래와 같이 수정합니다. 2번째 줄 부터 id/pass 설정이며, 콜론(:) 좌측이 id, 콜론 우측의 "" 부분이 패스워드입니다.
: RSA "privkey.pem"
alice : EAP "myPassword"
tom : EAP "tomPassword"
6.3 /etc/iptables.sav 파일 수정 (iptables 포워딩 설정)
포트 포워딩을 위해 iptables 저장 파일을 수정해 줍니다.
# Generated by iptables-save v1.6.1 on Mon Mar 4 21:22:51 2019
*nat
:PREROUTING ACCEPT [10:797]
:INPUT ACCEPT [1:104]
:OUTPUT ACCEPT [2:304]
:POSTROUTING ACCEPT [2:304]
-A POSTROUTING -s 10.10.1.0/24 -o eth0 -j MASQUERADE
-A POSTROUTING -o eth0 -j MASQUERADE
COMMIT
*filter
:INPUT ACCEPT [0:0]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [116:14048]
-A INPUT -i lo -j ACCEPT
-A INPUT -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp --dport 80 -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp --dport 443 -j ACCEPT
-A INPUT -i eth0 -p tcp -m tcp --dport 22 -j ACCEPT
# for strongswan
-A INPUT -i eth0 -p udp -m udp --dport 500 -j ACCEPT
-A INPUT -i eth0 -p udp -m udp --dport 4500 -j ACCEPT
-A INPUT -i eth0 -j DROP
COMMIT
*mangle
:PREROUTING ACCEPT [207:17257]
:INPUT ACCEPT [207:17257]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [116:14048]
:POSTROUTING ACCEPT [116:14048]
#-A PREROUTING -m conntrack --ctstate INVALID -j DROP
COMMIT
위에서 -A POSTROUTING -s 10.10.1.0/24 -o eth0 -j MASQUERADE 부분의 10.10.1.0/24 를 /etc/ipsec.conf 에서 설정한 주소와 동일하게 맞춰 줘야 합니다. 중간 부분의 # for strongswan 부분이 strongswan 에서 사용하는 포트입니다. 공유기를 사용할 경우 500번과 4500번 포트를 별도로 포트포워딩해 주어야 합니다.
파일 저장이 끝나면 아래 명령으로 iptables 에 변경 내용을 적용합니다.
iptables-restore < /etc/iptables.sav
6.4 ip 포워딩 기능을 활성화 해 줍니다.
/etc/sysctl.conf 파일에 net.ipv4.ip_forward=1 을 추가해 줍니다. 저장 후 아래의 명령어를 입력해서 적용합니다. # sysctl -p