CentOS/RHEL 8에 Hadoop 설치하기
Hadoop/설치Hadoop은 머신 클러스터에서 대규모 데이터 세트를 저장하고 처리하는 데 사용되는 무료 오픈 소스 및 Java 기반 소프트웨어 프레임 워크입니다. HDFS를 사용하여 데이터를 저장하고 MapReduce를 사용하여 이러한 데이터를 처리합니다. 주로 데이터 마이닝 및 머신 러닝에 사용되는 빅 데이터 도구의 생태계입니다. Hadoop Common, HDFS, YARN 및 MapReduce와 같은 네 가지 주요 구성 요소가 있습니다.
RHEL/CentOS 8에 Apache Hadoop을 설치하는 방법을 정리해 봅니다.
1. 서버 기본 설정
각각의 서버에서 공통적으로 해야 하는 설치 및 설정입니다
1.1 고정IP 설정
각각의 서버에 고정IP를 설정해 줍니다. (고정IP는 각각의 서비스 상황에 맞게 IP를 설정합니다. 여기서는 81~84를 부여합니다)
고정IP 설정을 위해 아래 명령으로 파일을 수정합니다:
vi /etc/sysconfig/network-scripts수정할 내용은 아래와 같습니다:
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none" <-- dhcp 를 none로 변경
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="enp1s0"
UUID="d5f41bf4-de0a-43b3-b633-7e2ec6212e58"
DEVICE="enp1s0"
ONBOOT="yes"
IPADDR=192.168.122.81 <-- 여기서 아래 부분 추가
PREFIX=24
GATEWAY=192.168.122.1
DNS1=192.168.122.1
DNS2=1.1.1.1
파일을 저장한 후 위의 DEVICE 부분의 인터페이스를 재시작 해서 IP를 변경내용을 적용합니다.
ifdown enp1s&& ifup enp1s0바뀐 IP가 제대로 적용되었는 지 아래 명령으로 확인합니다.
ip addr | grep enp1s02.2 hostname 설정
서비스를 구성하는 각각의 서버의 서버명을 설정합니다. (여기서는 4대의 서버로 hadoop01 ~ hadoop04로 설정합니다)
아래 명령으로 각각의 서버명을 설정해 줍니다:
hostnamectl set-hostname hadoop01hostname 설정이 되었다면 이제 각 서버마다 host명으로 접근이 가능하도록 /etc/hosts 파일에 추가해 줍니다.
다음 명령으로 /etc/hosts 파일을 수정합니다.
vi /etc/hosts아래와 같이 수정해 줍니다.
127.0.0.1 localhost
192.168.122.81 hadoop01
192.168.122.82 hadoop02
192.168.122.83 hadoop03
192.168.122.84 hadoop04
1.3 Java 설치
Hadoop 은 Java로 작성되었고 최신 버전은 Java11도 지원하지만 아직은 Java 8에서 안정적입니다. 아래와 같이 DNF를 이용해서 OpenJDK 8을 설치합니다:
dnf install java-1.8.0-openjdk.x86_64 ant -y설치 후 아래 명령으로 제대로 설치 되었는 지를 테스트 합니다:
java -version다음 출력이 나오면 OK:
openjdk version "1.8.0_262"
OpenJDK Runtime Environment (build 1.8.0_262-b10)
OpenJDK 64-Bit Server VM (build 25.262-b10, mixed mode)1.4 Hadoop 사용자 생성
보안을 생각해서 별도의 Hadoop 사용자를 생성합니다.
아래 명령어로 새로운 사용자를 생성합니다:
useradd -m hadoop다음으로 생성한 사용자의 암호를 설정해 줍니다:
passwd hadoop아래와 같이 사용자에 대한 암호를 2번 입력합니다:
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.1.5 Configure SSH Key-based Authentication
패스워드 없이 접속이 가능하도록 ssh 키를 설정합니다.
다음 명령으로 hadoop 유저로 로그인 합니다.
su - hadoop다음 명령으로 공개키와 개인키를 생성합니다.
ssh-keygen -t rsa아래와 같이 물어 보게 되는 데 엔터만 치면 됩니다.
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:a/og+N3cNBssyE1ulKK95gys0POOC0dvj+Yh1dfZpf8 hadoop@centos8
The key's randomart image is:
+---[RSA 2048]----+
| |
| |
| . |
| . o o o |
| . . o S o o |
| o = + O o . |
|o * O = B = . |
| + O.O.O + + . |
| +=*oB.+ o E|
+----[SHA256]-----+생성된 공개키를 로컬의 authorized_keys 에 추가하고 권한을 변경해 줍니다.
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 640 ~/.ssh/authorized_keys다음 명령으로 패스워드 없이 접속이 되는 지 확인해 봅니다.
ssh localhost처음 1번은 아래와 같이 호스트를 등록할 거냐고 물어 본니다. yes를 하고 엔터를 누르면 정상적으로 접속됩니다.
The authenticity of host 'localhost (::1)' can't be established.
ECDSA key fingerprint is SHA256:0YR1kDGu44AKg43PHn2gEnUzSvRjBBPjAT3Bwrdr3mw.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Activate the web console with: systemctl enable --now cockpit.socket
Last login: Sat Feb 1 02:48:55 2020
[hadoop@centos8 ~]$1.6 Hadoop 설치
다음 명령으로 hadoop 유저로 로그인 합니다.
su - hadoop아래 명령어로 하둡 최신 버전(여기서는 3.3.0)을 다운 받습니다.
wget http://apache.mirror.cdnetworks.com/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz다운이 완료되면 아래 명령어로 압축을 풀어 줍니다.
tar -xvzf hadoop-3.3.0.tar.gz아래와 같이 심볼릭 링크를 생성해 줍니다.
ln -s hadoop-3.3.0 hadoop이제 시스템의 Hadoop 과 Java 환경 변수를 설정해 줍니다.
아래 명령으로 ~/.bashrc 파일을 편집해 줍니다.
vi ~/.bashrc다음 라인을 추가해 줍니다.
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0/
export HADOOP_HOME=/home/hadoop/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"파일을 저장하고 다음 명령으로 스크립트를 실행해 줍니다.
source ~/.bashrc이번엔 하둡 환경변수 파일을 편집합니다.
vi $HADOOP_HOME/etc/hadoop/hadoop-env.sh아래와 같이 JAVA_HOME 변수를 찾아 수정해 줍니다.
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0/저장하고 닫아 줍니다. 이걸로 환경 설정은 끝입니다.
2. Single Node Cluster (유사분산 모드)
2.1 Configure Hadoop
먼저 Hadoop 홈 디렉토리 아래 namenode and datanode 디렉토리를 생성해야 합니다.
아래 명령으로 2개의 디렉토리를 생성해 줍니다:
mkdir -p ~/hadoopdata/hdfs/namenode
mkdir -p ~/hadoopdata/hdfs/datanode다음은 core-site.xml 파일에서 시스템 호스트명을 설정해 줍니다.:
vi $HADOOP_HOME/etc/hadoop/core-site.xml아래와 같이 자신의 시스템 호스트명을 설정해 줍니다.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
</configuration>파일을 저장 후 hdfs-site.xml 파일을 수정합니다:
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml아래 처럼 NameNode 와 DataNode 디렉토리를 설정해 줍니다:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hadoopdata/hdfs/datanode</value>
</property>
</configuration>파일을 저장합니다. mapred-site.xml 파일을 수정합니다:
vi $HADOOP_HOME/etc/hadoop/mapred-site.xml아래처럼 수정합니다:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
</configuration>파일을 저장하고, 이번에는 yarn-site.xml 파일을 수정합니다:
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml다음과 같이 변경합니다:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>저장하면 이제 다 되었습니다.
2.2 Start Hadoop Cluster
Hadoop 클러스터를 시작하기 전에 먼저 hadoop 사용자로 Namenode를 포맷해야 합니다.
Namenode를 포맷하기 위해 아래 명령어를 실행합니다:
hdfs namenode -format아래 내용이 표시되면 성공입니다:
2020-02-05 03:10:40,380 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
2020-02-05 03:10:40,389 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown.
2020-02-05 03:10:40,389 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.com/45.58.38.202
************************************************************/Namenode 포맷 후에, 아래 명령으로 hadoop 클러스트를 시작합니다:
start-dfs.shHDFS 성공적으로 시작되면, 아래와 같은 내용이 표시됩니다:
Starting namenodes on [hadoop.tecadmin.com]
hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [hadoop.tecadmin.com]다음으로 YARN 서비스를 시작합니다:
start-yarn.sh아래와 같은 메시지가 출력됩니다:
Starting resourcemanager
Starting nodemanagers2.2 상태 및 동작 확인
jps 명령으로 Hadoop 서비스의 상태를 체크해 볼 수 있습니다:
jps다음과 같이 실행중인 서비스가 표시됩니다:
7987 DataNode
9606 Jps
8183 SecondaryNameNode
8570 NodeManager
8445 ResourceManager
7870 NameNode아래 명령을 실행해서 잘 동작하는 지 확인해 봅니다:
cd $HADOOP_HOME
yarn jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar pi 16 1000정상적으로 실행되었다면 아래와 같이 표시 됩니다.
Job Finished in 36.294 seconds
Estimated value of Pi is 3.142500000000000000002.3 Configure Firewall
Hadoop은 포트 9870 과 8088을 사용하므로 이 포트들을 방화벽에서 허용해 주어야 합니다.
아래 명령으로 방화벽에서 허용해 줍니다:
firewall-cmd --permanent --add-port=9870/tcp
firewall-cmd --permanent --add-port=8088/tcp그리고 방화벽 규칙을 다시 로드해서 적용해 줍니다:
firewall-cmd --reload2.4 Access Hadoop Namenode and Resource Manager
웹브라우저를 열어 http://your-server-ip:9870 으로 Namenode에 접속합니다. 그럼 아래와 같은 화면이 표시됩니다:
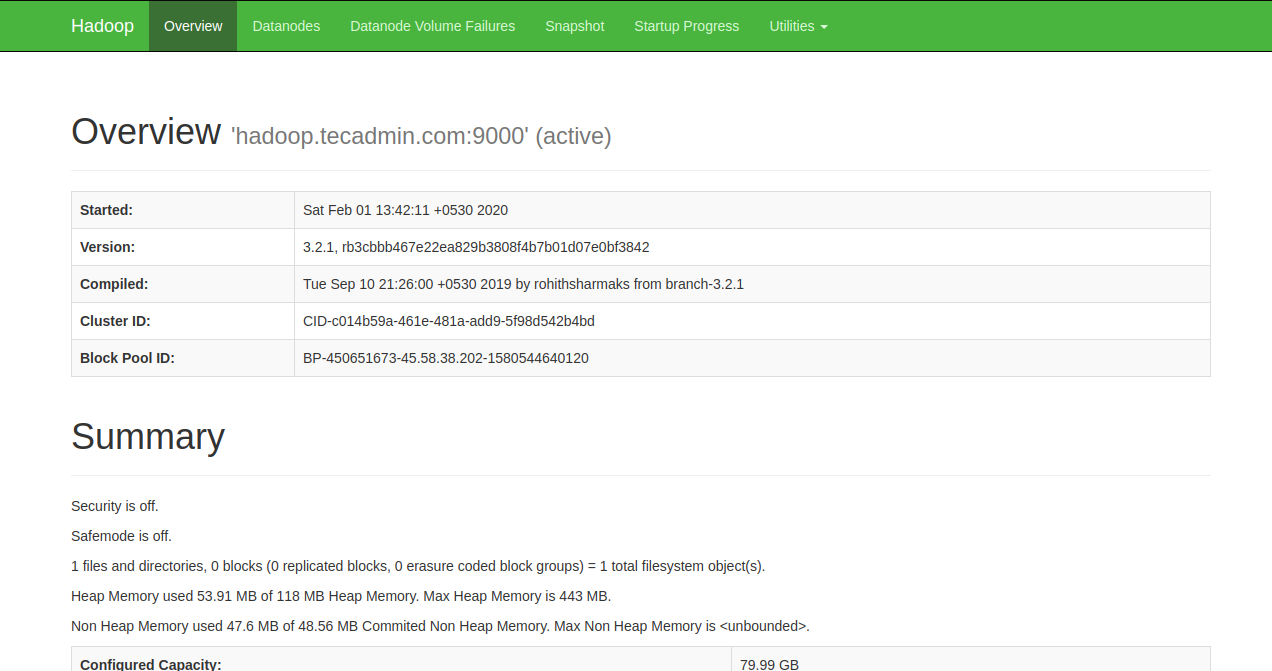
리소스 관리자에 접근하려면 http://your-server-ip:8088 로 접속합니다. 아래 화면이 표시됩니다:

2.5 Verify the Hadoop Cluster
Hadoop cluster 에 대한 설치 및 설정은 완료되었습니다. 이제 Hadoop을 테스트 하기 위해 HDFS 에 일부 디렉토리를 생성합니다.
다음 명령으로 테스트 디렉토리를 생성합니다:
hdfs dfs -mkdir /test1
hdfs dfs -mkdir /test2그리고 아래 명령으로 위 디렉토리를 표시합니다:
hdfs dfs -ls /다음과 같이 표시됩니다:
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2020-02-05 03:25 /test1
drwxr-xr-x - hadoop supergroup 0 2020-02-05 03:35 /test2웹의 Hadoop Namenode에서도 위 디렉토리가 표시되어야 합니다.
Namenode 웹페이지에서, Utilities => Browse the file system 을 클릭합니다. 아래와 같이 디렉토리가 표시되는 것을 확인할 수 있습니다:

2.6 분석 프로그램 실행
테스트를 위해 단어개수를 분석하는 예제를 실행합니다. 맵리듀스 job을 실행하기 위해서 HDFS 디렉토리를 생성합니다.
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/root
hdfs dfs -mkdir /user/root/conf
hdfs dfs -mkdir /input
hdfs dfs -copyFromLocal $HADOOP_HOME/README.txt /input
hdfs dfs -ls /input다음 명령으로 단어 개수를 분석하는 프로그램을 실행합니다:
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar wordcount /input/README.txt ~/wordcount-output실행이 완료되면 아래 명령으로 결과를 확인합니다:
hdfs dfs -ls ~/wordcount-output
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2020-09-03 03:43 /home/hadoop/wordcount-output/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 188 2020-09-03 03:43 /home/hadoop/wordcount-output/part-r-00000
hdfs dfs -cat ~/wordcount-output/part-r-00000다음과 같이 표시됩니다:
For 1
Hadoop, 1
about 1
and 1
at: 2
http://hadoop.apache.org/ 1
https://cwiki.apache.org/confluence/display/HADOOP/ 1
information 1
latest 1
our 2
please 1
the 1
visit 1
website 1
wiki, 12.7 Stop Hadoop Cluster
Hadoop Namenode 와 Yarn 서비스는 stop-dfs.sh 와 stop-yarn.sh 명령으로 중지할 수 있습니다.
아래 명령으로 Hadoop Namenode 서비스를 중지합니다:
stop-dfs.sh아래 명령으로 Hadoop Resource Manager 서비스를 중지합니다:
stop-yarn.sh3. Multi Node Cluster (완전 분산 모드)
지금까지의 작업으로 Single Node Cluster 로 동작하는 Hadoop 설치는 완료되었습니다. 이제는 여러대의 노드로 구성된 Hadoop 설정을 하도록 하겠습니다.
3.1 ssh 공개키 설정
아래 명령으로 master(hadoop01)의 공개키를 모든 datanode로 복사합니다:
scp -rp ~/.ssh/authorized_keys hadoop@hadoop02:~/.ssh/authorized_keys
scp -rp ~/.ssh/authorized_keys hadoop@hadoop03:~/.ssh/authorized_keys
scp -rp ~/.ssh/authorized_keys hadoop@hadoop04:~/.ssh/authorized_keys3.2 하둡 설정
3.2.1 master (마스터 노드) 설정
master 노드에서 hdfs-site.xml 파일을 수정합니다.
vi $HADOOP_HOME/etc/hadoop/hdfs-site.xml아래의 내용을 설정합니다.
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/hadoopdata/hdfs/namenode</value>
<final>true</final>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/hadoopdata/hdfs/datanode</value>
<final>true</final>
</property>
</configuration>master 노드에서 yarn-site.xml 파일을 수정합니다.
vi $HADOOP_HOME/etc/hadoop/yarn-site.xml아래의 내용을 설정합니다.
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop01:8031</value>
</property>
</configuration>아래 명령으로 workers 파일을 수정합니다.
vi $HADOOP_HOME/etc/hadoop/workers아래와 같이 설정해 줍니다.
hadoop02
hadoop03
hadoop043.2.1 slaves (슬레이브 노드) 설정
Master 설정 파일을 모두 슬레이브로 복사해 주어야 합니다.
아래 명령으로 복사해 줍니다.
scp $HADOOP_HOME/etc/hadoop/* hadoop02:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/* hadoop03:$HADOOP_HOME/etc/hadoop/
scp $HADOOP_HOME/etc/hadoop/* hadoop04:$HADOOP_HOME/etc/hadoop/아래 명령으로 기존 HDFS 저장소를 제거해 줍니다.
rm -rf ~/hadoopdata/hdfs/*3.3 방화벽 설정
Hadoop 은 내부적으로 랜덤하게 포트를 오픈하고 사용하므로, 다음 명령으로 같은 IP 대역에 대해 방화벽을 오픈해 줍니다. (Master/Slave 모두)
firewall-cmd --permanent --add-rich-rule='rule family="ipv4" source address=192.168.122.0/24 port port="80-65535" protocol="tcp" accept'다음 명령으로 방화벽을 다시 로드합니다.
firewall-cmd --reload3.4 동작
다음 명령으로 마스터 노드에서 Hadoop을 실행합니다.
start-dfs.sh정상적으로 실행되면 jps 명령으로 프로세스를 확인합니다. 정상이라면 아래와 같이 표시됩니다.
[hadoop@hadoop01 ~]$ jps
43112 SecondaryNameNode
43241 Jps
42876 NameNode각가의 Slave에서도 jps 명령으로 프로세스를 확인합니다. 정상이라면 아래와 같이 표시됩니다.
[hadoop@hadoop02 ~]$ jps
36262 Jps
36207 DataNode3.5 Multi Node 확인
웹브라우저에서 data node를 확인합니다. 아래처럼 3개가 표시되면 정상입니다.
